Top 10 Web Scraping Practice Sites (2023)
Are you looking to test your web scraping practical skills and looking for the best sites to test it out? Then read the article below to discover the best ...

Scraping Google for SEO is not as difficult as it seems. If you are interested, you can come in now and discover the best ways to scrape Google. In the article below, I discussed mor than 3 methods of scraping Google.
To accomplish their daily tasks, millions of individuals all over the world use Google every day. Individuals and businesses are now able to see answers in it like an encyclopedia. Currently, Google experiences over 83.9 billion visits per month, making it one of the most visited websites worldwide. Moreover, Google has an 87.35 percent market share worldwide and a market share of 61.4 percent among the top US search engine providers.
As such, Google is unmatched in a world where knowledge is power, and it offers access to a multitude of data. Since Google is the most secure search engine and the world's largest databank, it can be challenging to extract data from it. However, the good news is that there is a solution. There are useful ways to scrape Google, and I'll share a few of them with you in this article. But first, let's look at a summary of Google scraping.
To extract data from Google, including using APIs, web scraping, and downloading your data from Google products. Here are some popular methods:
- Google APIs: Many Google products offer APIs that allow you to access and extract data programmatically. For example, Google Analytics Data API
provides access to Google Analytics 4 report data, and Google Data Protocol is used in some older Google APIs.- Download your Google data: You can download your data from various Google products, such as Documents, Calendar, Photos, and YouTube videos, by following the instructions provided by Google Account Help
- Web scraping: You can use web scraping tools and libraries, such as Beautiful Soup in Python, to extract data from Google search results. However, scraping Google search results is against Google's terms of service, and you may face IP blocking or other consequences. An alternative is to use ready-made tools like the Google Search Results Scraper on the Apify platform, which allows you to scrape various elements from Google search results.
Table Of Contents
The process of gathering data from the Google website using automated tools or software is termed 'Google scraping.' We can also describe Google scraping as the process of gathering all the data based on search engine queries from the Google website.
Google does not permit free data scraping from its SERPs, in contrast to other websites that permit Google to use their web pages for their search engine system. Hence, Google arguably has one of the best anti-scraping solutions in the industry. As such, in order to scrape Google search result data, you need to be conscious of what you're doing and how to get past anti-spam filters.
There are, however, a number of techniques to scrape Google website data without getting banned. These techniques are applicable to both Google Maps data and search results from the Google search engine. In fact, these data sets are essential for SEO specialists and digital marketers. This is so that they can access keyword-based data. So, with that in mind, let's delve into some of the fundamentally great ways to scrape Google search results.
There is a wide range of public data on Google that can be scraped:
This data can give insights into trending topics, SEO performance, local business info, and more.
There are a good number of ways you can scrape data from Google. In this section of the article, I will discuss the popular options out there.
One of the best ways to extract Google's data is to develop a custom Google scraper in Python. Python happens to be one of the best programming languages for scraping. This is due to the fact that it makes it easy and fast to develop scripts for data collection. So, in this section, we'll go over how to use Python to quickly scrape the Google search results page.
1. You must first examine the website you plan to scrape to identify where to find the relevant elements before creating a Google scraper. The link Google creates as a result of a search query must first be taken into consideration.
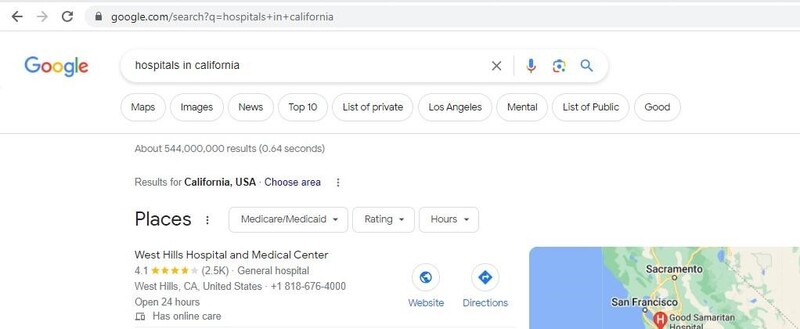
We can create the link ourselves because it is really straightforward. There will be no change to the 'https://www.google.com/search?q=' part. It would be followed by the search term with a '+' in place of a space.
2. Next, you have to figure out where the data that we need is located. In order to do this, right-click the screen and choose "Inspect" from the dropdown menu. You can also do this by simply pressing F12.
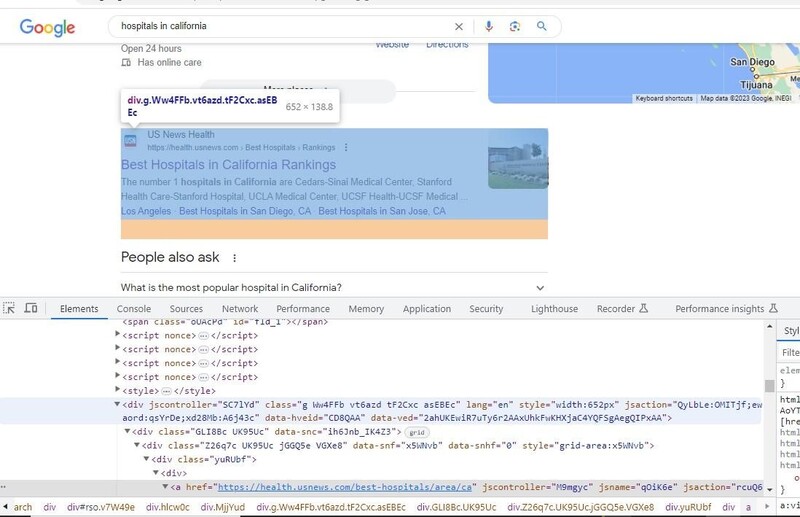
Most of the classes on the search engine result pages are, unfortunately, generated automatically. As such, getting the data by class name is difficult. The site's architecture, however, has not changed. So, the items in the search results still fall within the 'g' class.
3. The development environment must then be set up. Once you have examined the page and identified the components you wish to scrape, you can proceed. Setting up a suitable development environment for Python is important. Installing the required libraries and tools will allow you to effectively manage the data, submit queries to Google, and interpret HTML responses. So, make sure Python is installed on your computer.
4. The following code should be used to install the libraries required to build the Google Scraper:
pip install beautifulsoup4 pip install selenium pip install google-serp-api5. The pre-installed Python library requests will also be used in our script written in Python. But if for any reason you don't have it, you can use this command instead:
pip install requestsAlso, you can use the 'urllib' library rather than the'requests' library.
6. We can start extracting data from Google search results now that the development environment has been set up. The BeautifulSoup library will be used to parse and explore the HTML structure, while the requests library will be used to send HTTP requests to get the HTML response. Ensure that a new file is created and the libraries are connected.
import requests from bs4 import BeautifulSoup7. Set query headers to mask the scraper and lessen the chances of blocking:
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}Google's search results for mobile vs. desktop differ. So, you need to define the proper user agent based on the use case.
header={'User-Agent':"Mozilla/5.0 (Linux; Android 7.0; SM-G930V Build/NRD90M) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.125 Mobile Safari/537.36"}8. The current headers must be mentioned in the request. After that, we run the query and generate the outcome in a variable:
data = requests.get('https://www.google.com/search?q=hospitals+in+california', headers=header)I'll give the entire code and provide an explanation below to save time: import requests from bs4 import BeautifulSoup
url = 'https://www.google.com/search?q=hospitals+in+california'#For desktop
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}#For mobile
header={'User-Agent':"Mozilla/5.0 (Linux; Android 7.0; SM-G930V Build/NRD90M) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.125 Mobile Safari/537.36"} data = requests.get(url, headers=header) if data.status_code == 200: soup = BeautifulSoup(data.content, "html.parser") results = [] for g in soup.find_all('div', {'class':'g'}): anchors = g.find_all('a') if anchors: link = anchors[0]['href'] title = g.find('h3').text try: description = g.find('div', {'data-sncf':'2'}).text except Exception as e: description = "-" results.append(str(title)+";"+str(link)+';'+str(description)) with open("serp.csv", "w") as f: f.write("Title; Link; Description\n") for result in results: with open("serp.csv", "a", encoding="utf-8") as f: f.write(str(result)+"\n")So far, we've executed the query, produced a BeautifulSoup object, and parsed the page's resulting HTML code. Remember that the class of each element is "g." This would help you handle the data more effectively. To put it another way, this would gather all the elements with class 'g' and proceed one by one. This would scrape the required data from each one in order to go through all the elements. To do this, we created a 'for loop.'
Additionally, if you carefully examine the page's source code, you will notice that every element is a child of the tag, which houses the page link. That will allow us to retrieve the title, link, and description details. We have included the description in the try...except block after taking this possibility into account. Then, we enter the information regarding the components in the results variable.
You can make new files or edit existing ones that have the columns "Title," "Link," and "Description" in order to save the data. Finally, we entered each line of the result variable's data.
Another effective way to scrape Google data is to use the SERP API. So, you know, Google provides a wide range of open APIs for its many services. These APIs are typically JSON APIs based on RESTful requests. They are accessible to the public through the Google API GitHub repository. All of these APIs are free; however, they do have a lot of restrictions. The Custom Search API, for instance, provides the first 100 search queries each day without charge.
However, it will cost you $5 for every 1,000 requests you make if you need to make more queries. Also, even if you're willing to pay extra, you are limited to 10,000 requests every day. This is where third-party SERP APIs are useful, and I do recommend ScrapingBee's Google SERP API as a very trustworthy one.
With the help of this straightforward API, you can access over 1,000 free API credits. No credit card is required. With the help of this Google Search API, you can instantly scrape search results pages. All you need to do is;
After that, the API will reply with ready-to-use JSON data. Keep in mind that a successful API call costs you 25 API credits. Additionally, each unsuccessful search will be repeated as many times as possible for 30 seconds. So, while building your own code, please pay attention to the maximum timeout. Visit the documentation here to fully learn how to use ScrapingBee's Google SERP API.
For those looking to scrape Google data for one reason or another but do not have the knowledge of computer programming, this is for you. Visual scrapers, often known as no-code scrapers, are tools made for creating drag-and-drop web scraping bots. Without having to write code or scripts, these technologies also make it easier to change their functionality. These tools only connect to a URL and collect the information present on that page. To use them, you don't need any prior coding experience.
One popular one on the market is Octaparse. This tool can help you scrape the Google search results without coding. It can automatically scrape the data and save it in a well-organized format. Most of your Google scraping needs can be covered with the free edition of Octoparse. However, you can choose the commercial edition if you're interested in some additional features.
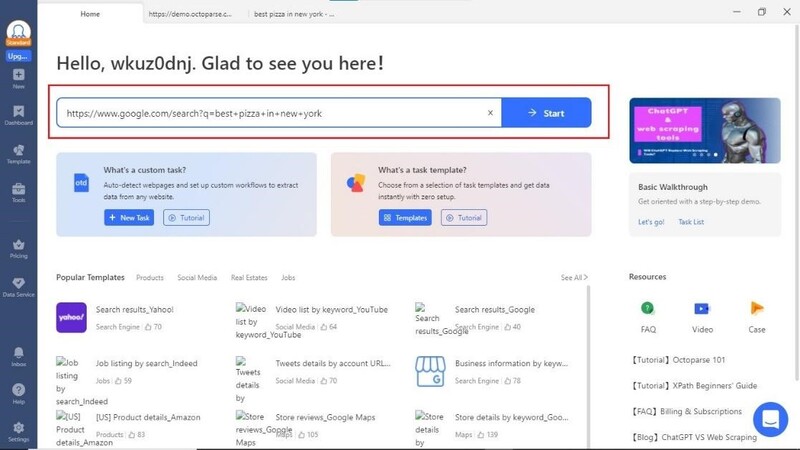
So, to use Octaparse,
1. You need to download and install it on your PC. After your installation, you can start by entering the Google URL in the Octoparse application and clicking on Start.
2. Octaparse would automatically scrape the Google search results for you.
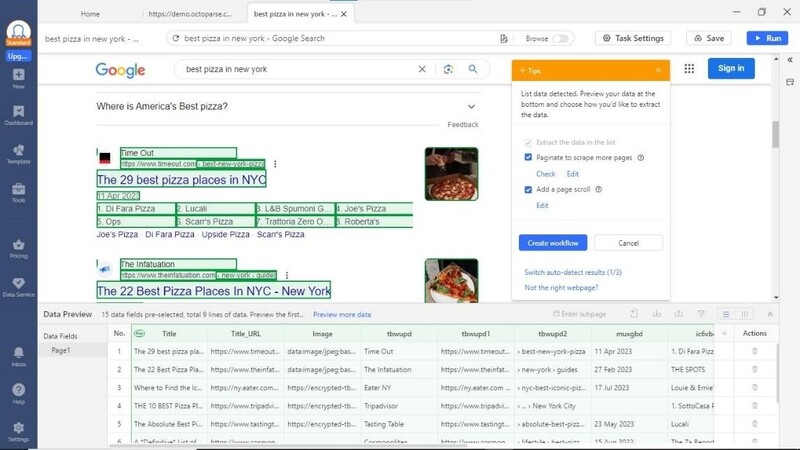
3. You can choose how you'd want to preview the data you just scraped using the Tip box in the upper right corner of the page. You can change the pagination and page scroll on that tip box. Once these criteria have been chosen, select 'Create workflow' to save the choices and automatically create the task workflow.
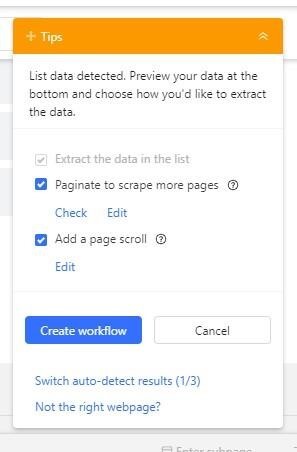
You should see a pop-up on the Tips Box that says the workflow has been created successfully. If you want, you can edit the ‘Next page’, ‘Load more', and 'Scroll' buttons as well.
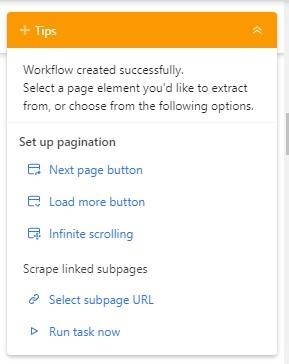
4. The next thing is to select the data that you need to extract. For instance, clicking on the first and second titles would automatically select all the other titles if we wanted to extract the title from the search result.
5. After you've finished choosing, click the 'Run' button at the top to begin the scraping process.

6. Choose whether you want to use your device or the cloud to execute the scraper.
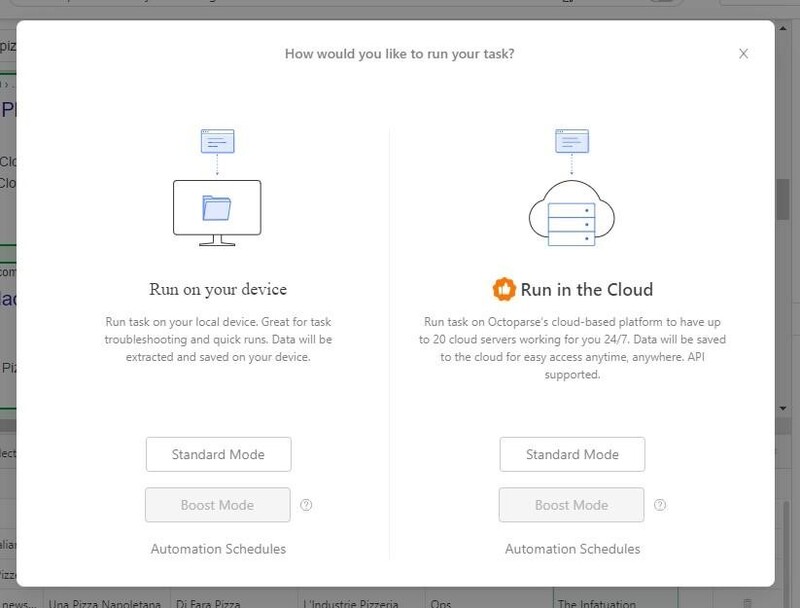
After the run is finished, you can click the "Export Data" option to download the data that has been scraped from the Google search results. This can be in XML, Excel, HTML, CSV, or JSON format. Also, the data can be exported to SQL Server, MySql, or Google Sheets.
Another code-free technique that can be used to scrape Google is the use of browser extensions. They are one of the simplest, straight-to-the-point ways to scrape Google search results. All you need to do is download the browser extension. They work just the same way visual web scrapers do. No coding is needed. One very good and reliable one to use is Data Miner. Using this Chrome and Edge browser extension, you can access and scrape data from Google into an Excel or CSV file format. This browser extension scraper's robust feature set lets you extract any text from Google search results pages that you see in the browser.
To scrape Google search results with Data Miner,
1. You need to first sign up and download the browser extension.
2. Next, open your browser and enter a query on Google.
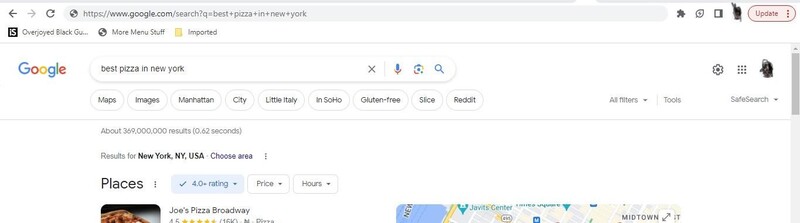
Keep in mind that Data Miner cannot scrape a website if it is not visible on the page. So, in the top-right corner of the browser, click the Data Miner extension. After that, click 'Scrape this page'.
3. Then select "Page Scrape." A list of recipes (recipes scrape data) is located on the left.
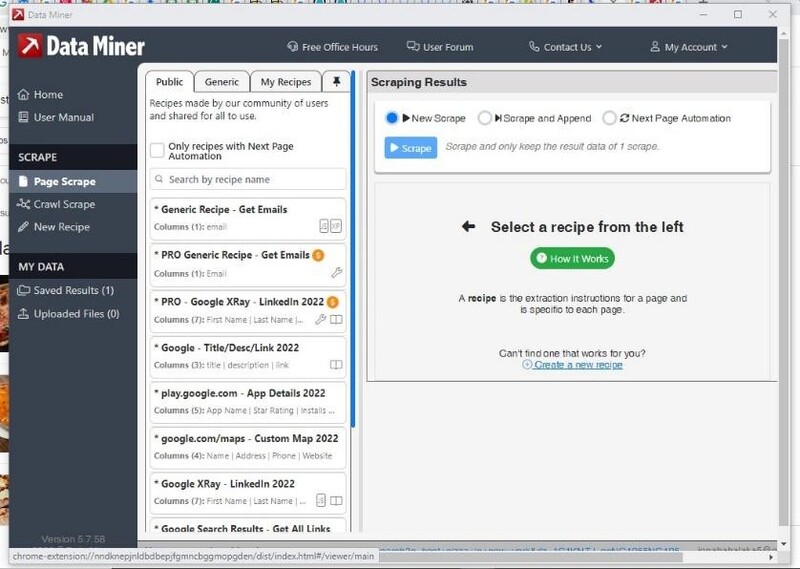
On the right, you will see three scraping methods. They are 'New Scrape', 'Rape and Append', and 'Next Page Automation'.
4. Hover on one of the recipes and click ‘Preview’.
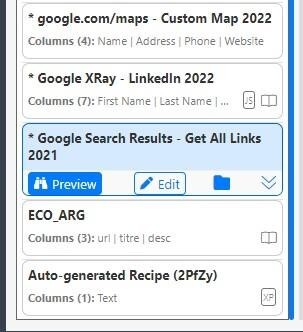
5. A preview of the data will appear on the right after choosing a recipe. Click 'Edit' to change the recipe's data if it needs to be corrected or modified.
6. Click the blue 'Scrape' button once you've decided on your scraping method. It will run the recipe and scrape the data.
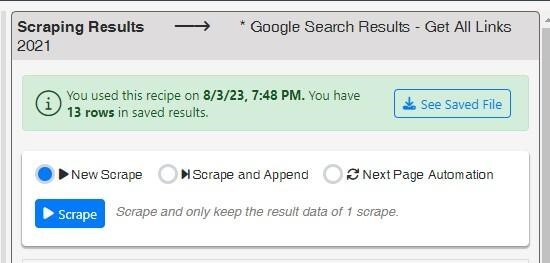
After scraping, the data is available for download as an Excel or CSV file or can be copied to the clipboard. Alternatively, rename the data and save it using Save As in Data Miner.
Google employs advanced bot detection systems across its properties. Challenges faced when scraping Google include:
Robust tools and approaches are required when scraping Google at scale.
Here are best practices for overcoming Google's anti-scraping mechanisms:
Specialized tools and services can simplify and automate Google scraping:
With the right approach, scraping Google data can provide valuable insights without getting your scrapers blocked. As always, comply with Google's terms of service and scrape ethically.
Publicly accessible Data from Google can be scraped legally. If you attempt to scrape more than that, you will encounter a challenge. So please inspect and review each web scraping project with the assistance of legal counsel. Please be aware that this is an overview of current legal developments regarding this topic and not legal advice.
Web scraping is not allowed by Google's terms of service, but there are a few exceptions for particular types of data and use cases. In spite of this, it's wise to exercise caution and attention when scraping data from Google. Pay close attention to their policies and terms of service. Nevertheless, you can use any of the ways we've listed above to make your Google scraping easier.
Google search results can be scraped in a number of ways. Using Google's APIs is one option. However, these APIs do have certain restrictions. So, you can scrape Google by writing your own Python scraper, using third-party APIs, or using no-code tools. In this article, I've gone into detail about a few of them. They are excellent ways to easily scrape Google search results pages.
Now we can see that no matter how challenging Google scraping can be, there is truly a way out. We have essentially covered every method that any individual trying to scrape Google can use. One or more of the methods I've mentioned would work for you, whether you're a programmer or not. I hope you will use the information in this article to your advantage and improve your scraping skills right away.